Wednesday, December 26, 2007
xUnit and Fitnesse
Fitnesse and NUnit.
One of the current arenas of competition in the testing arena is the comparison with xUnit style testing and Fitnesse style testing.
Fitnesse is good at allowing users to enter test cases so long as they conform to a programmed template. It also is good at presenting the results and what was tested in a presentable way, typically with a web page. The Fitnesse style frameworks I have come across are not good at summarising the results in a one page summary.
xUnit style testing aren’t good at allowing the users to enter test cases. However with frameworks like mbUnit, they are now quite good at allowing lots of test cases to share the same code. They are good at summarising the results, but bad a presenting what has been testing.
In my experience, it’s quite rare that end users actually enter the data in a Fitnesse test case. It’s the programmers who use a Fitnesse style interface to present their test cases to end users. My conclusion is that it’s the lack of a presentation layer that is the problem with xUnit style testing.
It’s certainly good practice to use command-query separation when designing code in order to make it easier to test.
I propose that there is an ‘Assert. Command method added to the Framework. It takes a string as an argument and it acts as comment for the command sections. There are already asserts in place.
Code
Output
So what does this presentation do? It presents a human readable output that can be presented to end users as to the details of what is going on in a test fixture. It’s the narrative of the test.
The Assert.Command passes when there are no failures between it and the end of the test or the next Assert.Command.
The count column lists the number of times the test has passed. Think about what happens when you have a loop. Typically here you would put a Assert.Command at the start of the loop. For example :-
Assert.Command (“Test all values in list”)
should probably the sort of comment that precedes each loop.
What then happens is each TestFixture, Test, Command and Assert can output their own little bit of XML that is then put together into a file at the end. You now have a narrative presentation that can be given to users, and they can read it, and make comments. They don’t need to understand the code underneath. In fact, the presentation is programming language neutral.
I’m not particularly happy with the presentation of the assertion details. Perhaps an expected value, against an actual value would be better. There is also the question of the message string in the assert.
Given the right presentation, where you can hide or expose the details, which isn’t difficult in an XML to HTML presentation, you end up with means of testing that does 99% of what Fitnesse does. It is just the question of allowing users to create their own test data.
One of the current arenas of competition in the testing arena is the comparison with xUnit style testing and Fitnesse style testing.
Fitnesse is good at allowing users to enter test cases so long as they conform to a programmed template. It also is good at presenting the results and what was tested in a presentable way, typically with a web page. The Fitnesse style frameworks I have come across are not good at summarising the results in a one page summary.
xUnit style testing aren’t good at allowing the users to enter test cases. However with frameworks like mbUnit, they are now quite good at allowing lots of test cases to share the same code. They are good at summarising the results, but bad a presenting what has been testing.
In my experience, it’s quite rare that end users actually enter the data in a Fitnesse test case. It’s the programmers who use a Fitnesse style interface to present their test cases to end users. My conclusion is that it’s the lack of a presentation layer that is the problem with xUnit style testing.
It’s certainly good practice to use command-query separation when designing code in order to make it easier to test.
I propose that there is an ‘Assert. Command method added to the Framework. It takes a string as an argument and it acts as comment for the command sections. There are already asserts in place.
Code
namespace bank
{
using NUnit.Framework;
[TestFixture]
public class AccountTest
{
[Test]
public void TransferFunds()
{
Assert.Command (“Create source account”)
Account source = new Account();
Assert.AreEqual(0.00F, source.Balance);
Assert. Command (“Deposit 200.00F in source account”)
source.Deposit(200.00F);
Assert.AreEqual(200.00F, source.Balance);
Assert. Command (“Create destination account”)
Account destination = new Account();
Assert.AreEqual(0.00F, destination.Balance);
Assert. Command (“Deposit 150.00F in destination account”)
destination.Deposit(150.00F);
Assert.AreEqual(150.00F, destination.Balance);
Assert. Command (“Deposit Transfer 100.00 from source to destination”)
source.TransferFunds(destination, 100.00F);
Assert.AreEqual(250.00F, destination.Balance);
Assert.AreEqual(100.00F, source.Balance);
}
}
}
Output
TestFixture AccountTest Status Count
Test TransferFunds Pass 1
Command Create source account Pass 1
Assert AreEqual(0.00F,source.Balance) Pass 1
Command Deposit 200.00F in source account Pass 1
Assert AreEqual(200.00F,source.Balance) Pass 1
Command Create destination account Pass 1
Assert AreEqual(0.00F, destination.Balance) Pass 1
Command Deposit 150.00F in destination account Pass 1
Assert AreEqual(150.00F, destination.Balance) Pass 1
Command Deposit Transfer 100.00 from source to destination Pass 1
Assert AreEqual(250.00F, destination.Balance) Pass 1
Assert AreEqual(100.00F, sort.Balance) Pass 1
So what does this presentation do? It presents a human readable output that can be presented to end users as to the details of what is going on in a test fixture. It’s the narrative of the test.
The Assert.Command passes when there are no failures between it and the end of the test or the next Assert.Command.
The count column lists the number of times the test has passed. Think about what happens when you have a loop. Typically here you would put a Assert.Command at the start of the loop. For example :-
Assert.Command (“Test all values in list”)
should probably the sort of comment that precedes each loop.
What then happens is each TestFixture, Test, Command and Assert can output their own little bit of XML that is then put together into a file at the end. You now have a narrative presentation that can be given to users, and they can read it, and make comments. They don’t need to understand the code underneath. In fact, the presentation is programming language neutral.
I’m not particularly happy with the presentation of the assertion details. Perhaps an expected value, against an actual value would be better. There is also the question of the message string in the assert.
Given the right presentation, where you can hide or expose the details, which isn’t difficult in an XML to HTML presentation, you end up with means of testing that does 99% of what Fitnesse does. It is just the question of allowing users to create their own test data.
Friday, November 30, 2007
Test Driven Development
A blog article on testing versus correctness
What I find odd about TDD is this. Most tests are just the same as exercising the contract that you would write if your language supported DBC (design by contract).
i.e. They consist of setting up data conforming to the preconditions, passing the data to the routine, then asserting the post condition as the success or failure of the test.
TDD then just tests a very small subset of the possible combinations.
DBC on the other hand is the equivalent of TDD full time (until disabled). All the time you are running this style of testing on your code, for all the scenarios that you exercise.
There are three approachs then to automating the testing for this style.
For Eiffel there's a research project Eiffel Test Studio that generates test data automatically that tries to generate all valid combinations of data that meet the pre-conditions, to see if you break the post-conditions. It should also be possible to see which post-conditions are used, and maybe even of there are possible missing post conditions.
There's a microsoft reasearch project Pex doing a similar thing. Exercise the function with lots of data automatically, but watch the program as it executes. Try and set the data up so you exercise each path through the code. ie. Explore all the cyclometric complexity of the code.
Lastly, there is the old fashioned code analysis route, much helped by DBC.
ie. Most TDD should be automated. Programmers need to move beyond just writting the tests.
We need to move to the point where we are writting the difficult tests, not the easy tests.
Its also clear that programmers are starting to use programs to automate their development, just as the program they write are designed to automate or aid other people's work.
What I find odd about TDD is this. Most tests are just the same as exercising the contract that you would write if your language supported DBC (design by contract).
i.e. They consist of setting up data conforming to the preconditions, passing the data to the routine, then asserting the post condition as the success or failure of the test.
TDD then just tests a very small subset of the possible combinations.
DBC on the other hand is the equivalent of TDD full time (until disabled). All the time you are running this style of testing on your code, for all the scenarios that you exercise.
There are three approachs then to automating the testing for this style.
For Eiffel there's a research project Eiffel Test Studio that generates test data automatically that tries to generate all valid combinations of data that meet the pre-conditions, to see if you break the post-conditions. It should also be possible to see which post-conditions are used, and maybe even of there are possible missing post conditions.
There's a microsoft reasearch project Pex doing a similar thing. Exercise the function with lots of data automatically, but watch the program as it executes. Try and set the data up so you exercise each path through the code. ie. Explore all the cyclometric complexity of the code.
Lastly, there is the old fashioned code analysis route, much helped by DBC.
ie. Most TDD should be automated. Programmers need to move beyond just writting the tests.
We need to move to the point where we are writting the difficult tests, not the easy tests.
Its also clear that programmers are starting to use programs to automate their development, just as the program they write are designed to automate or aid other people's work.
Monday, July 31, 2006
Dynamic Code Generation vs Reflection
Extract from an interesting code project article.
Dynamic Code Generation vs Reflection
Introduction
This is an example of how to use the new DynamicMethod class in .net 2.0 as an alternative to Reflection. Specifically, this example shows how to instantiate an object and get/set properties and fields on an object. As an added bonus, this code sample also allows getting and setting private fields and properties as well as instantiating objects with private constructors.
Background
At my current company we have built our own Object-Relational-Mapper (ORM), similar to nHibernate. In order to do this we were using reflection to set the properties/fields of an object with the values we retrieved from the database using a DataReader. Also, one of the features that was important to us was the ability to have “Read Only” properties on our objects. This involved setting the private field with our data mapper, instead of the public property. Unfortunately, reflection is a bit slow, especially when using it to set private values.
Solution
Fortunately, along came .Net 2.0 and the DynamicMethod class. This is a new class that allows one to create and compile code at run time. This approach is much faster then using reflection (see the times on the screen shot above). The down side to this approach is that you need to write your dynamic code using IL (as opposed to c#). But, with only a few lines of code we were able to create the desired effect.
Dynamic Code Generation vs Reflection
Introduction
This is an example of how to use the new DynamicMethod class in .net 2.0 as an alternative to Reflection. Specifically, this example shows how to instantiate an object and get/set properties and fields on an object. As an added bonus, this code sample also allows getting and setting private fields and properties as well as instantiating objects with private constructors.
Background
At my current company we have built our own Object-Relational-Mapper (ORM), similar to nHibernate. In order to do this we were using reflection to set the properties/fields of an object with the values we retrieved from the database using a DataReader. Also, one of the features that was important to us was the ability to have “Read Only” properties on our objects. This involved setting the private field with our data mapper, instead of the public property. Unfortunately, reflection is a bit slow, especially when using it to set private values.
Solution
Fortunately, along came .Net 2.0 and the DynamicMethod class. This is a new class that allows one to create and compile code at run time. This approach is much faster then using reflection (see the times on the screen shot above). The down side to this approach is that you need to write your dynamic code using IL (as opposed to c#). But, with only a few lines of code we were able to create the desired effect.
Tuesday, June 06, 2006
Unit Testing in Production
There are some unit tests that should be run in a production environment. Sounds heretical, but wait a moment.
fsck is the Unix file system checker. It checks the file system and reports on errors. At heart it is just a unit test that looks for faults in the file system.
Quite a few unit tests can be written to do the same. For example, read a database and check that it is consistent.
Take a collection of bonds, price them and check the prices against an external source.
All of these tests work on large data sets and should be available in a system. They are particularly useful after an upgrade has been installed.
I have even written tests to check that a system has been configured in the correct way.
fsck is the Unix file system checker. It checks the file system and reports on errors. At heart it is just a unit test that looks for faults in the file system.
Quite a few unit tests can be written to do the same. For example, read a database and check that it is consistent.
Take a collection of bonds, price them and check the prices against an external source.
All of these tests work on large data sets and should be available in a system. They are particularly useful after an upgrade has been installed.
I have even written tests to check that a system has been configured in the correct way.
Monday, June 05, 2006
More on Fitnesse
I've posted before on Fitnesse. Thinking more about it I think it does have one advantage over NUnit and unit testing.
When you are writing unit tests there are two ways that end up being used.
Fitnesse is different. The tests get written without any assumptions as to how the code is going to work. That is a significant difference.
When you are writing unit tests there are two ways that end up being used.
- Development phase - test first, then code
- Code coverage shows wholes in test strategy - code first, then write test
- Bugs - code first. Then when detected write the test to show its existance and a test to show it has been fixed.
Fitnesse is different. The tests get written without any assumptions as to how the code is going to work. That is a significant difference.
Thursday, June 01, 2006
Library Annoyances - Dot Net
I'm getting really annoyed with some of the design of libraries, and in particular Dot-Net.
If we take the simple task of converting a string into an integer. Clearly we can expected strings to be passed in that cannot be converted into an integer. Dot-Net takes the approach of generating an exception. OK, acceptable practice so far. However, there isn't a method anywhere that enables testing of strings to see if they can be converted to an integer.
You have to write this function yourself.
To have to write this every time such that you can write code in this way
Is really really annoying.
Having an IsInteger function also means that writing unit tests becomes a lot easier.
It also means that you can attempt to put in place preconditions and post conditions in routines.
What is happening is that programmers haven't be brought up with Design By Contract where this sort of function is normal, because it will be used as a pre or post condition. This is one reason why the function should also be side effect free. If you know Eiffel then you will program this way automatically.
Similarly, they haven't thought about the need for functions in unit tests. Here you don't want to be messing around with exceptions unless you are testing an exception framework. You want clean code.
There is the implied connection between unit testing and DBC. Both are needed. Unit testing to exercise the code. DBC to test the code, when ever it is run, not just in a unit test.
If we take the simple task of converting a string into an integer. Clearly we can expected strings to be passed in that cannot be converted into an integer. Dot-Net takes the approach of generating an exception. OK, acceptable practice so far. However, there isn't a method anywhere that enables testing of strings to see if they can be converted to an integer.
Public Function IsInteger(text as String) as Boolean
You have to write this function yourself.
Public Function IsInteger(text as String) as Boolean
Dim i As Integer
Try
i = CDbl(text) ' or use the convert Class
Return True
Catch
Return False
End Try
End Function
To have to write this every time such that you can write code in this way
If IsInteger(text) then
...
Else
... ' Handle error
End If
Is really really annoying.
Having an IsInteger function also means that writing unit tests becomes a lot easier.
It also means that you can attempt to put in place preconditions and post conditions in routines.
What is happening is that programmers haven't be brought up with Design By Contract where this sort of function is normal, because it will be used as a pre or post condition. This is one reason why the function should also be side effect free. If you know Eiffel then you will program this way automatically.
Similarly, they haven't thought about the need for functions in unit tests. Here you don't want to be messing around with exceptions unless you are testing an exception framework. You want clean code.
There is the implied connection between unit testing and DBC. Both are needed. Unit testing to exercise the code. DBC to test the code, when ever it is run, not just in a unit test.
NCoverExplorer
I've been using NCoverExplorer as part of Testdriven.Net for some agile development. However, last night I found a bug. I sent the stack trace off to the support address. Grant writes back quickly. I send him some information about how to replicate the problem. New version is released within 2 hours of the initial bug report.
Thanks Grant. Appreciated.
Thanks Grant. Appreciated.
Wednesday, May 31, 2006
A simple object DB
Create a database with a schema like this relationship diagram.
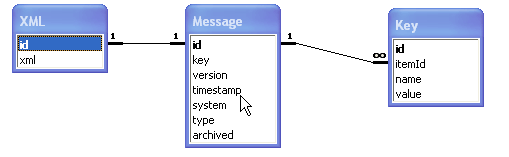
Now we can easily create the following application.
When a trade message arrives, we store it in the XML table. At the same time, we run an XSLT style sheet on the message. This generates some of the fields in the Message table. In particular it generates the type of message, the time stamp, and the key. We then update the message table with a new row. This update method has to be a little clever in that it needs to work out if there is a row already in place with the same key. If so, it sets the version number to the next in sequence If not, it sets the message number to 1.
That in itself is sufficient to act as a message store of free form XML. Notice there isn't any normalisation of the data. The XML can change, and the application carries on working. At the same time, you don't have to analyse the data and normalise it in order to get it into the database. For something like a swap transaction that would be a lot of work.
So storage is easy. What about retrieval? Well, here we again can have an easy strategy. We create a set of keys to the data and store them in the key table. To generate the keys, we resort to the same method used to generate the key on the Message table. We take the XML, pass it through an XSLT style sheet, and have the
style sheet output just the keys. A small amount of programming and we have the keys generated.
Now we can retrieve by keys.
One likely scenario is the need to add extra keys. Again it isn't a problem. We have the original message. We need to iterate over the Message table. We clean out the old keys. We take the XML message and pass it through the new XSLT style sheet, and generate the new keys and store them.
As a pattern this is a very cute idea.
1. Nothing is specific to one particular application.
2. XSLT is the right approach for manipulating XML
3. The schema copes with changes in requirements without the need to be modified.
4. The pattern removes the need for lots of analysis to get the data into a persistent store.
The split between Message and XML tables is to speed up access by removing the CLOB data to the XML table. Quite often you will not need to query the XML table.
An extension is indicated by the archived flag. You may want to age data and even move it off into an archive table. Alternatively set up the indexes with the archived flag as part of the key to speed up access.
One use is as a message store for systems that don't support idempotent operations
Another is as a message archive to keep records of messages over the long term. Just attach an adapter onto a message queue and store the messages.
Use of the version number also means you can have a full record of the messages.
Version could be made a key, but the problem here is that you often just want the latest version. It is easier and quicker having this as part of the message table.

Now we can easily create the following application.
When a trade message arrives, we store it in the XML table. At the same time, we run an XSLT style sheet on the message. This generates some of the fields in the Message table. In particular it generates the type of message, the time stamp, and the key. We then update the message table with a new row. This update method has to be a little clever in that it needs to work out if there is a row already in place with the same key. If so, it sets the version number to the next in sequence If not, it sets the message number to 1.
That in itself is sufficient to act as a message store of free form XML. Notice there isn't any normalisation of the data. The XML can change, and the application carries on working. At the same time, you don't have to analyse the data and normalise it in order to get it into the database. For something like a swap transaction that would be a lot of work.
So storage is easy. What about retrieval? Well, here we again can have an easy strategy. We create a set of keys to the data and store them in the key table. To generate the keys, we resort to the same method used to generate the key on the Message table. We take the XML, pass it through an XSLT style sheet, and have the
style sheet output just the keys. A small amount of programming and we have the keys generated.
Now we can retrieve by keys.
One likely scenario is the need to add extra keys. Again it isn't a problem. We have the original message. We need to iterate over the Message table. We clean out the old keys. We take the XML message and pass it through the new XSLT style sheet, and generate the new keys and store them.
As a pattern this is a very cute idea.
1. Nothing is specific to one particular application.
2. XSLT is the right approach for manipulating XML
3. The schema copes with changes in requirements without the need to be modified.
4. The pattern removes the need for lots of analysis to get the data into a persistent store.
The split between Message and XML tables is to speed up access by removing the CLOB data to the XML table. Quite often you will not need to query the XML table.
An extension is indicated by the archived flag. You may want to age data and even move it off into an archive table. Alternatively set up the indexes with the archived flag as part of the key to speed up access.
One use is as a message store for systems that don't support idempotent operations
Another is as a message archive to keep records of messages over the long term. Just attach an adapter onto a message queue and store the messages.
Use of the version number also means you can have a full record of the messages.
Version could be made a key, but the problem here is that you often just want the latest version. It is easier and quicker having this as part of the message table.
![]()
Subscribe to Posts [Atom]