Wednesday, May 31, 2006
A simple object DB
Create a database with a schema like this relationship diagram.
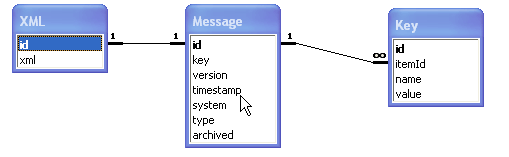
Now we can easily create the following application.
When a trade message arrives, we store it in the XML table. At the same time, we run an XSLT style sheet on the message. This generates some of the fields in the Message table. In particular it generates the type of message, the time stamp, and the key. We then update the message table with a new row. This update method has to be a little clever in that it needs to work out if there is a row already in place with the same key. If so, it sets the version number to the next in sequence If not, it sets the message number to 1.
That in itself is sufficient to act as a message store of free form XML. Notice there isn't any normalisation of the data. The XML can change, and the application carries on working. At the same time, you don't have to analyse the data and normalise it in order to get it into the database. For something like a swap transaction that would be a lot of work.
So storage is easy. What about retrieval? Well, here we again can have an easy strategy. We create a set of keys to the data and store them in the key table. To generate the keys, we resort to the same method used to generate the key on the Message table. We take the XML, pass it through an XSLT style sheet, and have the
style sheet output just the keys. A small amount of programming and we have the keys generated.
Now we can retrieve by keys.
One likely scenario is the need to add extra keys. Again it isn't a problem. We have the original message. We need to iterate over the Message table. We clean out the old keys. We take the XML message and pass it through the new XSLT style sheet, and generate the new keys and store them.
As a pattern this is a very cute idea.
1. Nothing is specific to one particular application.
2. XSLT is the right approach for manipulating XML
3. The schema copes with changes in requirements without the need to be modified.
4. The pattern removes the need for lots of analysis to get the data into a persistent store.
The split between Message and XML tables is to speed up access by removing the CLOB data to the XML table. Quite often you will not need to query the XML table.
An extension is indicated by the archived flag. You may want to age data and even move it off into an archive table. Alternatively set up the indexes with the archived flag as part of the key to speed up access.
One use is as a message store for systems that don't support idempotent operations
Another is as a message archive to keep records of messages over the long term. Just attach an adapter onto a message queue and store the messages.
Use of the version number also means you can have a full record of the messages.
Version could be made a key, but the problem here is that you often just want the latest version. It is easier and quicker having this as part of the message table.

Now we can easily create the following application.
When a trade message arrives, we store it in the XML table. At the same time, we run an XSLT style sheet on the message. This generates some of the fields in the Message table. In particular it generates the type of message, the time stamp, and the key. We then update the message table with a new row. This update method has to be a little clever in that it needs to work out if there is a row already in place with the same key. If so, it sets the version number to the next in sequence If not, it sets the message number to 1.
That in itself is sufficient to act as a message store of free form XML. Notice there isn't any normalisation of the data. The XML can change, and the application carries on working. At the same time, you don't have to analyse the data and normalise it in order to get it into the database. For something like a swap transaction that would be a lot of work.
So storage is easy. What about retrieval? Well, here we again can have an easy strategy. We create a set of keys to the data and store them in the key table. To generate the keys, we resort to the same method used to generate the key on the Message table. We take the XML, pass it through an XSLT style sheet, and have the
style sheet output just the keys. A small amount of programming and we have the keys generated.
Now we can retrieve by keys.
One likely scenario is the need to add extra keys. Again it isn't a problem. We have the original message. We need to iterate over the Message table. We clean out the old keys. We take the XML message and pass it through the new XSLT style sheet, and generate the new keys and store them.
As a pattern this is a very cute idea.
1. Nothing is specific to one particular application.
2. XSLT is the right approach for manipulating XML
3. The schema copes with changes in requirements without the need to be modified.
4. The pattern removes the need for lots of analysis to get the data into a persistent store.
The split between Message and XML tables is to speed up access by removing the CLOB data to the XML table. Quite often you will not need to query the XML table.
An extension is indicated by the archived flag. You may want to age data and even move it off into an archive table. Alternatively set up the indexes with the archived flag as part of the key to speed up access.
One use is as a message store for systems that don't support idempotent operations
Another is as a message archive to keep records of messages over the long term. Just attach an adapter onto a message queue and store the messages.
Use of the version number also means you can have a full record of the messages.
Version could be made a key, but the problem here is that you often just want the latest version. It is easier and quicker having this as part of the message table.
Tuesday, May 30, 2006
Fitnesse versus Unit Testing
My feelings on Fitnesse are as follows. I don't think users want to use html to design tests. Users really want to see the results of unit tests presented in a way they can understand. The easiest mechanism for them to use is to see the results as html on a web page, and such that they can see or trust that the tests have been run.
Unit tests are not very good in this respect. There is no standard way for test inputs, test outputs, and the result of the test to be presented back to the user.
Given this was in place, I doubt that Fitnesse would be an attractive option.
So as a guess, it would work something like this in NUnit
Output should be in the form of XML, with a style sheet and optional XSLT sheet to transform to XHTML.
I have seen people try and use Fitnesse as a precondition tester for the system as a whole. For example, has all the requisite static data been set up. Fitnesse can test to see if known static data has been set up. However, if you provide a report in the system for displaying the static data, you have a much more useful result.
The real test is a reconciliation test. Does the data in a particular system reconcile against a gold standard of static data.
ie. So far in my limited experience of Fitnesse, all the testing problems are better solved using standard regression testing techniques, particularly if there are some useful extensions provided do the testing frameworks.
Unit tests are not very good in this respect. There is no standard way for test inputs, test outputs, and the result of the test to be presented back to the user.
Given this was in place, I doubt that Fitnesse would be an attractive option.
So as a guess, it would work something like this in NUnit
OutputTestName (name)
OutputTestParameter(name,value)
...
OutputTestResult (name,value)
OutputTestAnswer (boolean)
...
Output should be in the form of XML, with a style sheet and optional XSLT sheet to transform to XHTML.
I have seen people try and use Fitnesse as a precondition tester for the system as a whole. For example, has all the requisite static data been set up. Fitnesse can test to see if known static data has been set up. However, if you provide a report in the system for displaying the static data, you have a much more useful result.
The real test is a reconciliation test. Does the data in a particular system reconcile against a gold standard of static data.
ie. So far in my limited experience of Fitnesse, all the testing problems are better solved using standard regression testing techniques, particularly if there are some useful extensions provided do the testing frameworks.
Monday, May 29, 2006
NUnit - A deficiency
NNnit is a great tool.
However, it has one deficiency. As far as I can tell, you cannot easily write data driven tests that appear in the results.
If I have a file, that contains test a value and a result, I can read the file line by line (or use xml). I can then test function f
The test is then
The problem is that each line will not be tested. The test fails on the first failure.
At the same time, I only see one result in the output - test.
It would be better to have all lines appear as tests in the output.
Perhaps something like this.
However, it has one deficiency. As far as I can tell, you cannot easily write data driven tests that appear in the results.
If I have a file, that contains test a value and a result, I can read the file line by line (or use xml). I can then test function f
The test is then
< Test() > _
Sub Test
for each line
assert.IsEqual(line.result, f(line.value))
next line
End Sub
The problem is that each line will not be tested. The test fails on the first failure.
At the same time, I only see one result in the output - test.
It would be better to have all lines appear as tests in the output.
Perhaps something like this.
< Dynamictest() > _
Sub Test()
for each line
StartTest("f(" + line.value + ")"
assert.IsEqual(line.result, f(line.value))
EndTest
next line
End Sub
Saturday, May 27, 2006
Effective Date and Notice Date
If we consider an accounts package, it is very common for details of transactions, entries, to be entered after they have taken place. There are two dates that need to be recorded. First is the date and time the transaction is entered. Second there is the effective date, or the date on which the transaction happened.
Given these dates there are some quite complex queries that can be written that answer some difficult questions.
For example, we can ask the question, what were the accounts at the end of January?
We can also ask what should the accounts have been at the end of January?
Very subtle difference between 'were' and 'should'.
There is another feature of accounts. Accountants like to close the accounts for a period. That means they don't want to accept any new entries where the effective date is earlier than the period end.
So lets say we want to close the books for the end of the year. We allow entries to be made up to the end of January, but after that we will close the books.
The first question will be what are the accounts at the end of the year.
All very simple.
It is also important to know what adjustments were made after year end.
All simple.
There are two approaches to locking the accounts down. One is to not allow any entries made after the end of January with an effective date in the last year. That is no back valued transactions that affect the previous end of year accounts. The alternative is to allow them, and change the queries.
The end of year accounts then become.
Here then 31-JAN-2006 is the closing date of the books.
You can continue making adjustments to the previous year's books. However, the entry screen should warn that this is happening.
We then add one more query. Next closing of the books, we need to know the adjustments to the previous year's accounts.
and the actual accounts themselves uses the same query
Just with the addition of two dates, we can get queries that distinguish between two important questions, what should have been the state and what was the state.
Given these dates there are some quite complex queries that can be written that answer some difficult questions.
For example, we can ask the question, what were the accounts at the end of January?
Select * from Entries where notice_date <= #31-JAN-2006#We can also ask what should the accounts have been at the end of January?
Select * from Entries where effective_date <= #31-JAN-2006#Very subtle difference between 'were' and 'should'.
There is another feature of accounts. Accountants like to close the accounts for a period. That means they don't want to accept any new entries where the effective date is earlier than the period end.
So lets say we want to close the books for the end of the year. We allow entries to be made up to the end of January, but after that we will close the books.
The first question will be what are the accounts at the end of the year.
Select * from Entries where effective_date <= #31-DEC-2006#All very simple.
It is also important to know what adjustments were made after year end.
Select * from Entries where effective_date <= #31-DEC-2006# and notice_date > #31-DEC-2006#All simple.
There are two approaches to locking the accounts down. One is to not allow any entries made after the end of January with an effective date in the last year. That is no back valued transactions that affect the previous end of year accounts. The alternative is to allow them, and change the queries.
The end of year accounts then become.
Select * from Entries where effective_date <= #31-DEC-2006# and notice_date <= #31-JAN-2006#Here then 31-JAN-2006 is the closing date of the books.
You can continue making adjustments to the previous year's books. However, the entry screen should warn that this is happening.
We then add one more query. Next closing of the books, we need to know the adjustments to the previous year's accounts.
Select * from Entries where effective_date <= #31-DEC-2007# and notice_date > #31-JAN-2006#and the actual accounts themselves uses the same query
Select * from Entries where effective_date <= #31-DEC-2007#Just with the addition of two dates, we can get queries that distinguish between two important questions, what should have been the state and what was the state.
Friday, May 26, 2006
Time times for commuting
Travel-time Maps and their Uses: "Transport maps and timetables help people work out how to get from A to B using buses, trains and other forms of public transport. But what if you don't yet know what journey you want to make? How can maps help then?
This may seem a strange question to ask, but it is one we all face in several situations:
Where would I like to work?
Where would I like to live?
Where would I like to go on holiday?
These are much more complicated questions than those about individual journeys, but one thing they all have in common is transport: can I get to and from the places I'm considering quickly and easily?
The maps on this page show one way of answering that question. Using colours and contour lines they show how long it takes to travel between one particular place and every other place in the area, using public transport. They also show the areas from which no such journey is possible, because the services are not good enough."
A great idea that I've been thinking about for a while. All they need to do is turn it into a production system.
What I couldn't work out was an easy way to get the travel time. What this group has done is interesting. They have used a proxy for the travel time. They picked the time taken to arrive at a place at 9.00 am. In other words, the time most likely to be used by people when using the map in the first place.
What is needed is a website for this to be built where you can input details of your journeys. Reading the article it looks like the Ordnance Survey is fulfilling its government brief of making money out of the taxpayer for something that the taxpayer has already paid for. All government information should be free.
One extension I can think of is this. You might have a set of transport needs. My commute to work, visiting my parents, travelling to my favourite shops and restaurants, playing sport. I should be able to set up these journeys and give them a weight. Now the isochrones for each journey can be calculated, multiplied by the weighting and totaled. That then gives me the locations that minimise or optimise my transport needs.
This may seem a strange question to ask, but it is one we all face in several situations:
Where would I like to work?
Where would I like to live?
Where would I like to go on holiday?
These are much more complicated questions than those about individual journeys, but one thing they all have in common is transport: can I get to and from the places I'm considering quickly and easily?
The maps on this page show one way of answering that question. Using colours and contour lines they show how long it takes to travel between one particular place and every other place in the area, using public transport. They also show the areas from which no such journey is possible, because the services are not good enough."
A great idea that I've been thinking about for a while. All they need to do is turn it into a production system.
What I couldn't work out was an easy way to get the travel time. What this group has done is interesting. They have used a proxy for the travel time. They picked the time taken to arrive at a place at 9.00 am. In other words, the time most likely to be used by people when using the map in the first place.
What is needed is a website for this to be built where you can input details of your journeys. Reading the article it looks like the Ordnance Survey is fulfilling its government brief of making money out of the taxpayer for something that the taxpayer has already paid for. All government information should be free.
One extension I can think of is this. You might have a set of transport needs. My commute to work, visiting my parents, travelling to my favourite shops and restaurants, playing sport. I should be able to set up these journeys and give them a weight. Now the isochrones for each journey can be calculated, multiplied by the weighting and totaled. That then gives me the locations that minimise or optimise my transport needs.
Thursday, May 25, 2006
Bidirectional Debugger
Undo Software announces UndoDB: "A bidirectional debugger allows programmers to run a program backwards in time as well as forwards. The program can be stepped back line-by-line, or rewound to any point in its history. Furthermore, programmers can play the program forwards and backwards in a totally repeatable fashion, allowing them to 'home in' on the cause of a bug.
Bidirectional debuggers are much more powerful than their traditional counterparts, which only allow programmers to step their programs forwards in time. This is particularly true for bugs whose root cause occurs long before the ill effects manifest themselves, and for bugs that occur only intermittently. "
This is an interesting idea. Debugging both ways!
"With this analogy, a programmer using a bidirectional debugger is like the detective finding detailed CCTV footage not just of the murder itself, but also all pertinent events that led to the murder."
Bidirectional debuggers are much more powerful than their traditional counterparts, which only allow programmers to step their programs forwards in time. This is particularly true for bugs whose root cause occurs long before the ill effects manifest themselves, and for bugs that occur only intermittently. "
This is an interesting idea. Debugging both ways!
"With this analogy, a programmer using a bidirectional debugger is like the detective finding detailed CCTV footage not just of the murder itself, but also all pertinent events that led to the murder."
Saturday, May 13, 2006
Martin Fowler - Code Ownership
Martin Fowler - Code Ownership: "There are various schemes of Code Ownership that I've come across. I put them into three broad categories:
Strong code ownership breaks a code base up into modules (classes, functions, files) and assigns each module to one developer. Developers are only allowed to make changes to modules they own. If they need a change made to someone else's module they need to talk to the module owner and get them to make the change. You can accelerate this process by writing a patch for the other module and sending that to the module owner.
Weak code ownership is similar in that modules are assigned to owners, but different in that developers are allowed to change modules owned by other people. Module owners are expected to take responsibility for the modules they own and keep an eye on changes made by other people. If you want to make a substantial change to someone else's module it's polite to talk it over with the module owner first.
Collective code ownership abandons any notion of individual ownership of modules. The code base is owned by the entire team and anyone may make changes anywhere. You can consider this as no code ownership, but it's advocate prefer the emphasis on the notion of ownership by a team as opposed to an individual."
This is an interesting observation. Psychologically, people like strong code ownership. If you take a pride in your work, it is almost inevitable.
I have worked on weak code ownership as a system. Forced integrations every two weeks. Negotiations with the other owners for changes to their code. Integrator is responsible for resolving other issues.
However, as you move towards continuous integration, I think there is more justification for collective ownership. After all, you still get the psychological satisfaction of knowing who broke the code! :-)
Strong code ownership breaks a code base up into modules (classes, functions, files) and assigns each module to one developer. Developers are only allowed to make changes to modules they own. If they need a change made to someone else's module they need to talk to the module owner and get them to make the change. You can accelerate this process by writing a patch for the other module and sending that to the module owner.
Weak code ownership is similar in that modules are assigned to owners, but different in that developers are allowed to change modules owned by other people. Module owners are expected to take responsibility for the modules they own and keep an eye on changes made by other people. If you want to make a substantial change to someone else's module it's polite to talk it over with the module owner first.
Collective code ownership abandons any notion of individual ownership of modules. The code base is owned by the entire team and anyone may make changes anywhere. You can consider this as no code ownership, but it's advocate prefer the emphasis on the notion of ownership by a team as opposed to an individual."
This is an interesting observation. Psychologically, people like strong code ownership. If you take a pride in your work, it is almost inevitable.
I have worked on weak code ownership as a system. Forced integrations every two weeks. Negotiations with the other owners for changes to their code. Integrator is responsible for resolving other issues.
However, as you move towards continuous integration, I think there is more justification for collective ownership. After all, you still get the psychological satisfaction of knowing who broke the code! :-)
![]()
Subscribe to Posts [Atom]